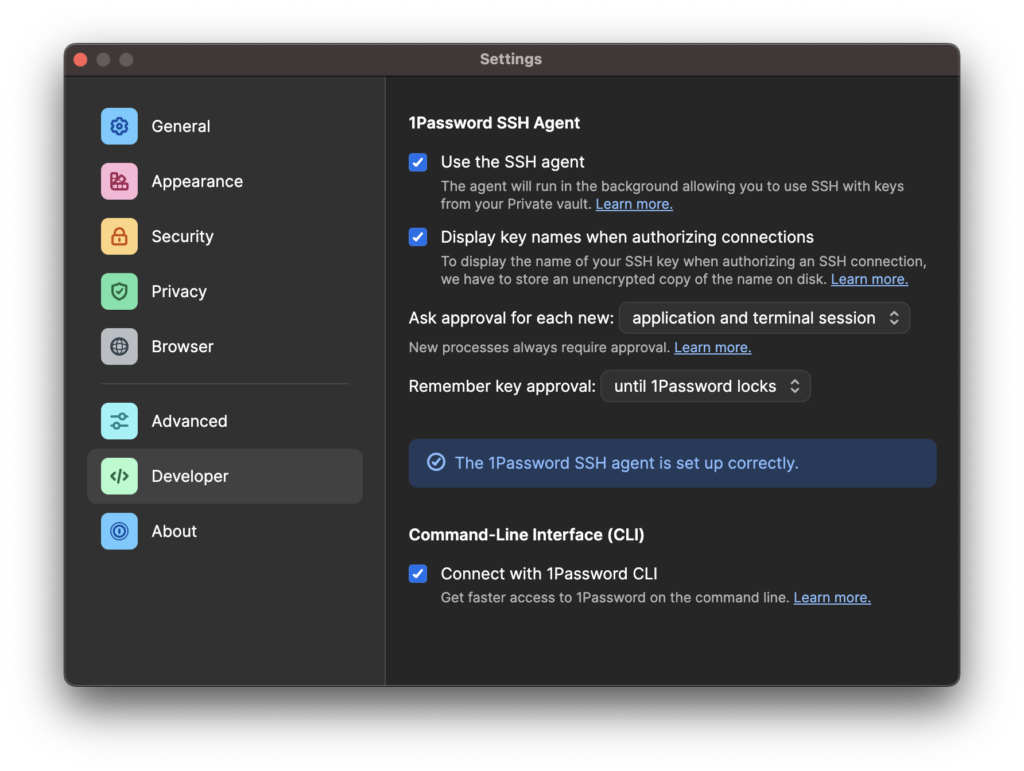
I’ve had Alfred search issues on my M1 MacBook Pro when it came to trying to run applications installed by JetBrains Toolbox. I used the Alfred self-diagnostics tool to figure out what was going on with one of the apps, Rider, and received the output below:
Starting Diagnostics...
File: 'Rider.app'
Path: '/Users/bergren2/Applications/JetBrains Toolbox'
-----------------------------------------------------------
Check file cache database...
✅ File cache integrity is ok
-----------------------------------------------------------
Check if file is readable...
✅ Alfred has permissions to read this file.
Unix Permissions: 493
Underlying Type: NSFileTypeDirectory
Extended Attributes: (
"com.apple.macl",
"com.apple.provenance",
"com.apple.quarantine"
)
-----------------------------------------------------------
Check if volume '/' is indexed by macOS...
✅ Indexing is enabled on this drive
-----------------------------------------------------------
Check direct file metadata...
⚠️ Direct metadata is missing, this file is likely not indexed by macOS
Display Name:
Other Names:
Content Type:
Last Used:
-----------------------------------------------------------
Check mdls file metadata...
❌ macOS metadata missing essential items
kMDItemFSContentChangeDate = 2023-01-20 02:20:40 +0000
kMDItemFSCreationDate = 2023-01-20 02:20:40 +0000
kMDItemFSCreatorCode = ""
kMDItemFSFinderFlags = 0
kMDItemFSHasCustomIcon = 0
kMDItemFSInvisible = 0
kMDItemFSIsExtensionHidden = 0
kMDItemFSIsStationery = 0
kMDItemFSLabel = 0
kMDItemFSName = "Rider.app"
kMDItemFSNodeCount = 1
kMDItemFSOwnerGroupID = 20
kMDItemFSOwnerUserID = 501
kMDItemFSSize = 1
kMDItemFSTypeCode = ""
-----------------------------------------------------------
❌ Troubleshooting failedThe root of the issue was that the application wasn’t showing up in Spotlight, so I took to the Internet to search for a way to re-index or add the application. It led me to run this:
mdimport ~/Applications/And while this seemed to do the trick, I was still getting the instance of Rider that exists in ~/Library/Application, but only in Alfred. And Alfred is supposed to ignore it! So knowing that Spotlight was correct — it was only showing the version in ~/Applications/ — I typed “reload” into Alfred to reload the cache and remove the extra instance.
I first became an Alfred user back when Spotlight wasn’t as powerful, and tools like it and Quicksilver were a must-have. Now? I’m not so sure. However Alfred has become a staple part of my workflow, even when it comes to generating GUIDs or quickly opening Jira links when I have ticket ID. And remember Ubiquity for Firefox? Most of that functionality is replicated just fine in Alfred, but I still dream about highlighting an address and seeing it pop up on a map. That was peak Late Aughts.
Edit: I ran into issues indexing core Mac apps — things like Mail.app and Messages.app weren’t showing in Spotlight. It turns out they aren’t actually in /Applications and are instead in /System/Applications — you can easily verify this in terminal using ls on the respective directories. The solution was to delete ~/Library/Preferences/com.apple.spotlight.plist and restart, which I found out about through this guide. Now that I know that this file was being buggy, I wouldn’t be surprised if it was another buggy casualty of the transfer from my old MacBook Pro.